
一、Spark 介绍及生态
Spark是UC Berkeley AMP Lab开源的通用分布式并行计算框架,目前已成为Apache软件基金会的顶级开源项目。至于为什么我们要学习Spark,可以总结为下面三点:
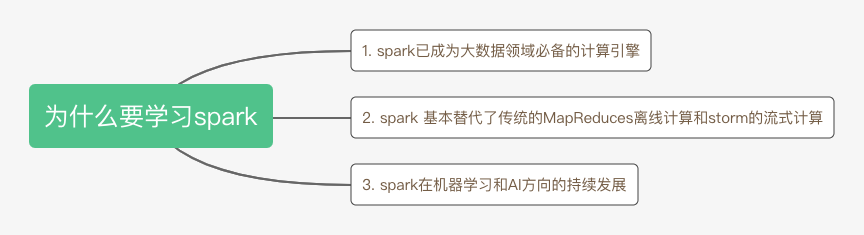
1. Spark相对于hadoop的优势
(1)高性能
Spark具有hadoop MR所有的优点,hadoop MR每次计算的中间结果都会存储到HDFS的磁盘上,而Spark的中间结果可以保存在内存,在内存中进行数据处理。
(2)高容错
基于“血统”(Lineage)的数据恢复:spark引入了弹性分布式数据集RDD的抽象,它是分布在一组节点中的只读的数据的集合,这些集合是弹性的且是相互依赖的,如果数据集中的一部分的数据发生丢失可以根据“血统”关系进行重建。
CheckPoint容错:RDD计算时可以通过checkpoint进行容错,checkpoint有两种检测方式:通过冗余数据和日志记录更新操作。在RDD中的doCheckPoint方法相当于通过冗余数据来缓存数据,而“血统”是通过粗粒度的记录更新操作来实现容错的。CheckPoint容错是对血统检测进行的容错辅助,避免“血统”(Lineage)过长造成的容错成本过高。
Comments