
Pinot 是一个实时分布式的 OLAP 数据存储和分析系统。使用它实现低延迟可伸缩的实时分析。Pinot 从脱机数据源(包括 Hadoop 和各类文件)和在线数据源(如 Kafka)中获取数据进行分析。Pinot 被设计成可进行水平扩展。Pinot 特别适合这样的数据分析场景:查询具有大量维度和指标的时间序列数据、分析模型固定、数据只追加以及低延迟,以及分析结果可查询。本文介绍了 Pinot 在Uber 的应用情况。
引言
Uber 有一个复杂的“市场”,由乘客、司机、食客、餐厅等组成。在全球范围内运营该市场需要实时的情报和决策。例如,识别延迟的 Uber Eats 订单或放弃的购物车有助于我们的社区运营团队采取纠正措施。对于日常运营、事件分类和财务情报来说,拥有一个包含不同事件的实时仪表板是至关重要的,这些事件包括消费者需求、司机可用性或城市中发生的行程等等。
在过去的几年里,我们已经建立了一个自主服务平台来支持这样的用例,以及 Uber 不同部门的许多其他用例。该平台的核心构件是 Apache Pinot,这是一个分布式的在线分析处理(OnLine Analytical Processing,OLAP)系统,该系统用于对 TB 级数据执行低延迟的分析查询。在本文中,我们介绍了这一平台的细节,以及它如何融入 Uber 的生态系统。我们重点介绍了 Pinot 在 Uber 内部的演变,以及我们如何从少数用例扩展到多集群,全主动部署,为数百个用例提供支持,以毫秒级的延迟查询 TB 级规模的数据。
用例概述
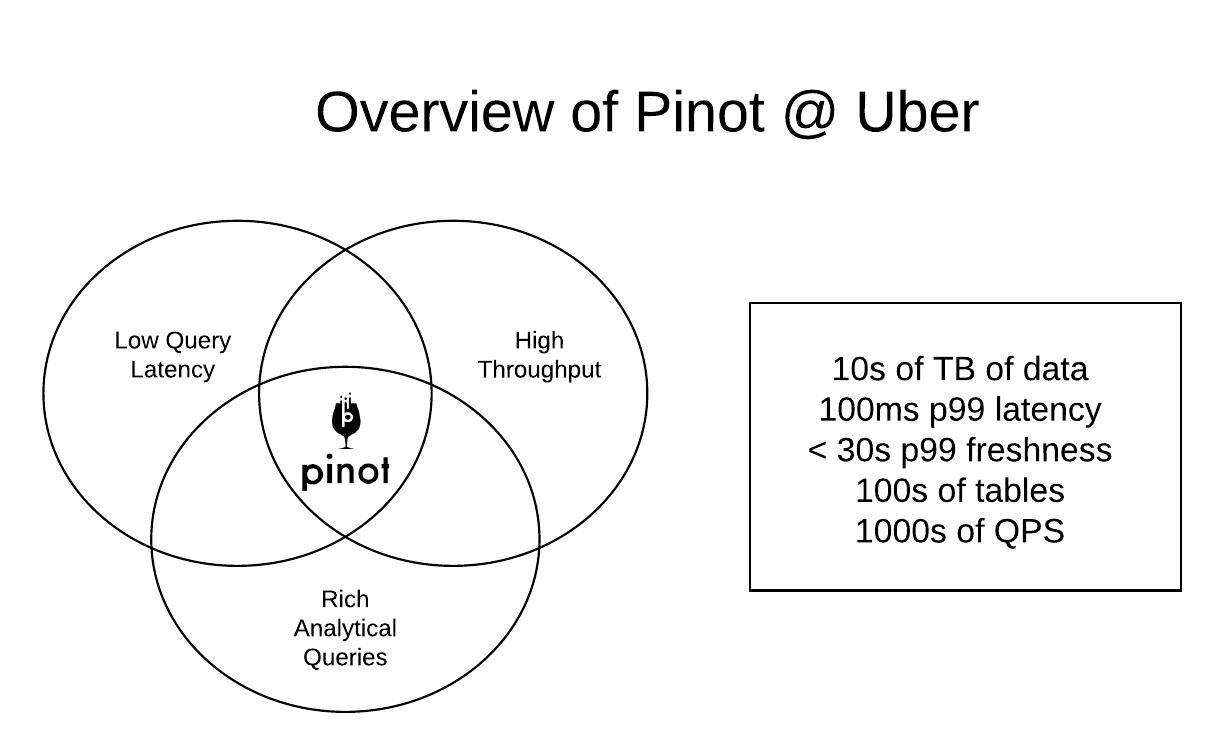
上图描述了实时分析用例的典型需求。Uber 内部的不同用例可以分为以下几个大类:
- 仪表板
- 分析应用程序
- 近实时探索
仪表板
Uber 的许多工程团队使用 Ponot 为各自的产品构建定制的仪表板。Uber Eats Restaurant Manager(餐厅经理)就是其中的一个例子:
Comments