
针对中文命名实体识别(NER)中存在的分词信息缺失等问题,小米AI实验室NLP平台团队近期提出一种新颖的多孔词格模型PLTE(PorousLatticeTransformerEncoder)。
多孔词格模型PLTE基于优化后的Transformer编码器,将分词信息有效地融入到字符级别的命名实体识别模型中,在保证识别效果的同时,识别效率可达到Lattice-LSTM命名实体识别模型的11.4倍。配合预训练模型,PLTE效果更佳。
目前该工作已经被COLING 2020接收,论文链接https://arxiv.org/abs/1911.02733。本工作与中国科学院信息工程研究所柳厅文老师、西湖大学张岳老师合作完成。
背景
命名实体识别任务可以建模为序列标注问题,其中实体边界和类别标签被联合预测。不同于英文命名实体识别,中文没有明显的词边界,导致命名实体识别任务更加困难。一种直观的方法是先分词再进行词级别的序列标注,但这种方法会造成分词的错误传递;另一种是直接基于字符级别的序列标注,但这种方法忽略了词级别的信息;第三种折衷的方法是把词信息融入到基于字符级别的序列标注中,这种方法包括数据融合(例如分词和NER进行多任务学习)和结构融合(例如通过修改模型结构直接将词典融入到训练过程)。其中结构融合最具代表性的工作是Lattice-LSTM[1]模型,该模型结构如下图所示:
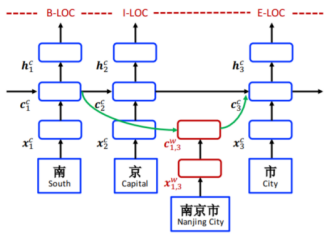
Comments