
1. 使用 Kylin 的缘由
爱奇艺 OLAP 服务演变
爱奇艺大数据 OLAP 服务演变的过程可以用如下架构图说明:
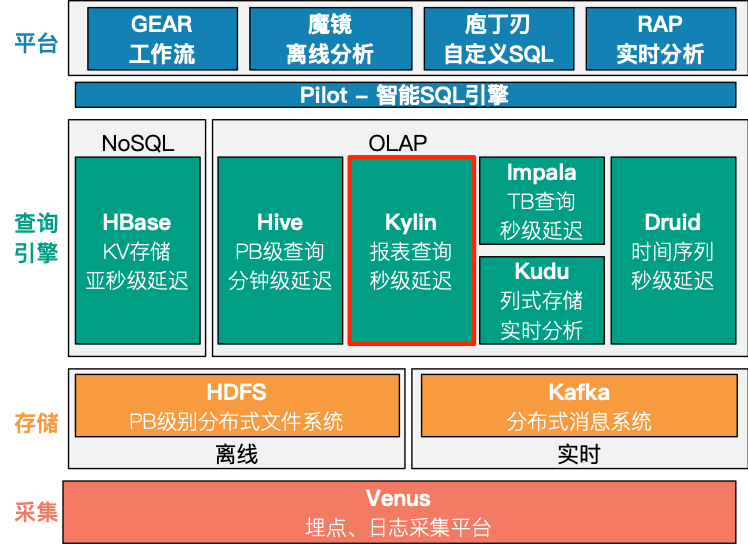
数据处理流程分为如下 几个层级:
- 最下方是采集平台,收集业务的埋点和日志;
- 数据按时效性分为两种类型:离线类型的灌入到 HDFS,实时数据灌入到 Kafka;
- 往上是各种分析引擎,Hive 用于 PB 级别的离线分析,Kylin 用于每日报表,针对相对固定的维度进行分析,Impala 用户 Ad-hoc 场景,Kudu 支持实时更新和分析,Druid 针对的是实时事件流;
- 在这些引擎之上是统一的 SQL 引擎 – Pilot,负责引擎和数据源的智能路由,基于此构建了 BI 分析平台,工作流平台,自定义 SQL 查询平台,实时分析平台等。
爱奇艺发展的大体时间线,2015 年前以离线分析为主,技术上是经典的 Hive + MySQL 方案,但缺点是报表查询比较慢,而且数据时效性差;2016 - 2018 年致力于将查询耗时提升至交互式级别,分为两大类:Kylin 针对固定报表,在维度比较有限的情况下,通过一个预处理,TB 级别数据延时能在秒级,而 Impala 则针对 Ad-hoc 类场景,可以查询任意明细数据;2018 年以后从离线往实时去发力,其中 Kudu 支持实时插入和更新,Druid 支持事件流场景。
Kylin 典型需求
数据分析中一个典型场景是 用户行为分析,譬如用户在 APP 上进行一次点击,采集之后进行分析。下面为一个示例 SQL,分析首页过去一天的展示次数。
SELECT COUNT(1) as cnt
FROM hive_table_user_act
WHERE act_type = 'display’
AND page = 'home'
AND dt = '2020-07-18';
此类查询传统是用 Hive 表去做分析,具有如下几个特点:
Comments