
导读: 网易大数据平台的底层数据查询引擎,选用了Impala作为OLAP查询引擎,不但支撑了网易大数据的交互式查询与自助分析,还为外部客户提供了商业化的产品与服务。今天将为大家分享下Impala在网易大数据的优化和实践。
01 Impala的定位及优势
Impala有哪些优势,让我们选择Impala作为网易内部的OLAP查询引擎?
1. Impala在数据处理中的角色
先来看一下Impala在数据处理中的角色。
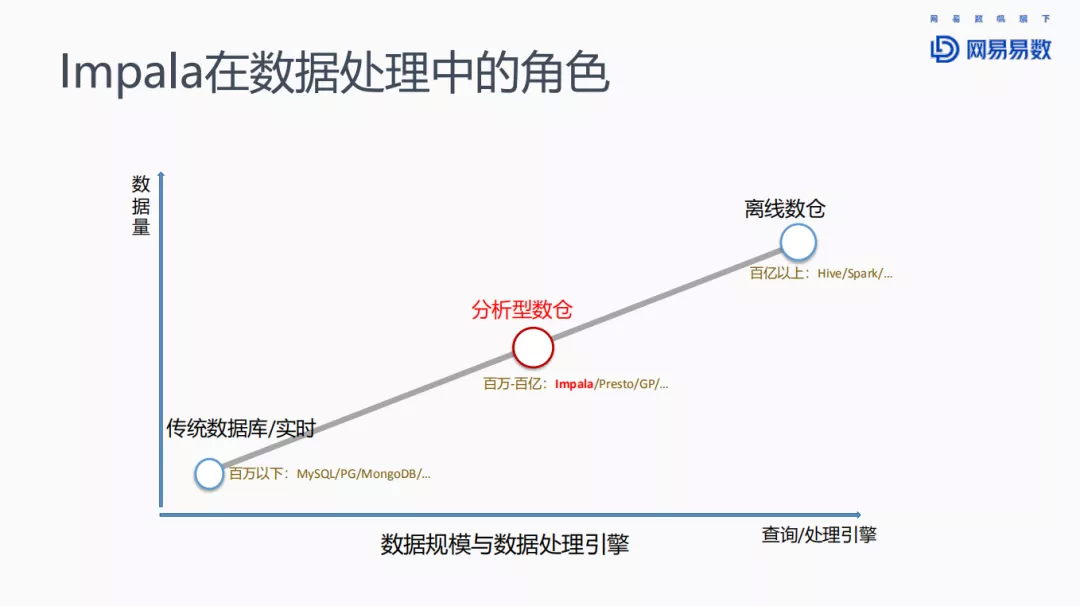
对于数据量较少的场景,例如百万数据以下的情况,可以采用传统的关系型数据库,如MySQL或者PostgreSQL等,或者一些文档数据库,比如MongoDB等。随着数据量的增大,达到上亿级别时,一般选择分析型数仓来存储,并使用OLAP引擎来查询。此等规模的数据查询,对响应时间的要求虽然比关系型数据库要低,但一般也要求在秒级返回查询结果,不能有太大的延迟。Impala、Presto、Greenplum等都在此列。当规模继续扩大到上百亿以上时,则会选择批处理引擎,如Hive、Spark来进行数据处理。
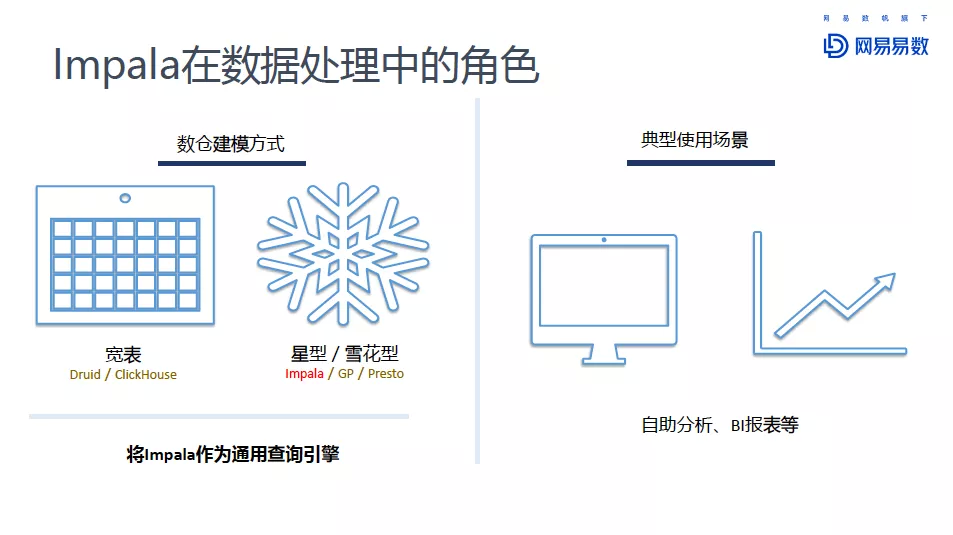
今天分享的Impala就是针对分析型数仓的查询引擎。分析型数仓有很多种建模方式。
Comments