
前言
TalkingData 是一家总部在北京的数据智能服务提供商,通过提供数据智能产品和服务,来帮助企业获得对消费者行为、偏好和倾向的洞察。TalkingData的一项重要服务是基于机器学习的用户行为分析:通过分析用户信息,可以为用户提供更具有价值的广告。比如有一个汽车经销商想要为想买车的用户投放最近的促销信息,他可以通过这个产品来找到在未来三个月有买车倾向的用户群,进而定向投放广告。最开始,TalkingData的模型是基于XGBoost构建的。后来随着技术演进和精度要求的提升,TalkingData研发部门进一步开发了基于深度学习模型的应用。经过实验以及测试论证,他们的数据科学家成功用PyTorch将模型的recall rate(recall rate是模型在阈值下是否能够提供推理的比例)提升了13%。换句话说,相比于传统机器学习模型,他们的深度学习模型在基于相同的精度情况下可以带来更多的深度学习推理结果。
但是TalkingData在大规模部署深度学习应用中遇到了很大的挑战:模型需要每天对数亿的数据进行深度学习推理。为了能够更高效地进行大规模计算,他们使用了基于Apache Spark的大规模分布式架构来快速批量推理。可是,由于Spark主要是基于JVM的框架,使用Python应用(PySpark) 进行深度学习推理往往会造成内存溢出问题。因为基于JVM本身的内存管理很难去对一个Python的进程产生影响。在过去,因为XGBoost对于Java的支持,TalkingData可以使用XGBoost Java API在Spark平台进行部署。现今使用了PyTorch,由于没有一个很好设计的Java API,以及各种内存溢出问题,他们没有办法在Apache Spark上调用PyTorch模型进行推理任务。这导致了他们被迫转向使用一个GPU的实例来单独进行深度学习推理,这种方案大大增加了后期维护成本。
通过这篇文章,TalkingData发现了AWS基于Java开发的深度学习框架DJL(Deep Java Library)可以很好的解决上述的困境。在这个博客中,我们将带领大家了解TalkingData部署的模型,以及他们是如何利用DJL在Apache Spark上实现生产环境部署深度学习模型。这个解决方案最终将之前的生产架构简化,一切任务都可以在Apache Spark轻松运行,总时间也减少了66%。从长远角度上,这也显著节省了维护成本。
关于模型
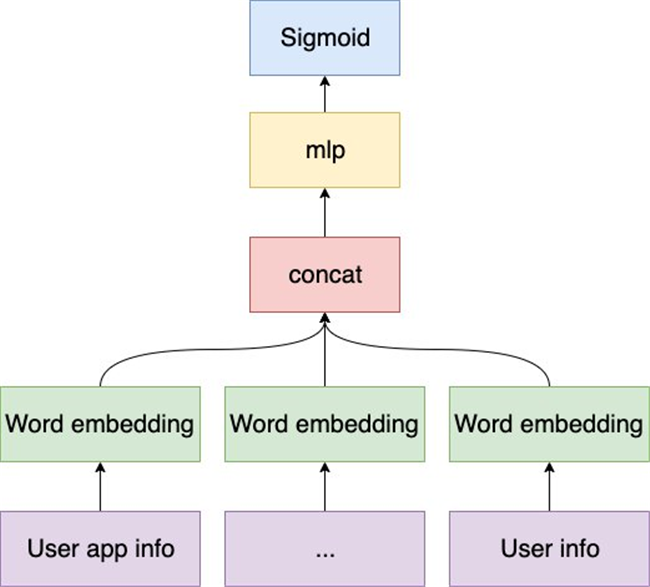
该模型为一个用于推断活跃用户是否有可能购买汽车的二分类模型,使用的特征来自于嵌入TalkingData SDK的应用收集的数据。在将原始数据聚合和处理的过程中,特征不可避免地会成为稀疏的分类特征。当TalkingData使用传统的机器学习模型(例如逻辑回归和XGBoost)时,这些简单的模型在从这些稀疏的特征中学习的过程中很容易过拟合。 另外,考虑到数以百万计的训练数据可以支持更复杂,更强大的模型,TalkingData将其模型升级为了DNN(深度神经网络)模型。
Comments