
微软和谷歌一直积极致力于训练深度神经网络的新模型,并推出了各自的新框架,Microsoft PipeDream和Google GPipe。二者使用了类似的原理来扩展深度学习模型的训练能力,具体细节在相应的研究论文中分别给出(参见PipeDream和GPipe的论文)。
作为深度学习生命周期中的一个组成环节,训练工作在模型扩展到一定规模时是十分具有挑战性的。虽然训练一个实验性的基本模型相对简单,但训练的复杂性会随模型的质量和规模呈线性增长。例如,在2014年ImageNet视觉识别竞赛中,具有400万参数的GoogleNet以74.8%的正确率胜出。三年后,2017年ImageNet竞赛的胜出者SENet(Squeeze-and-Excitation Networks)给出了82.7%的正确率,但模型规模增大了36倍多,达1.458亿个参数。同一时期,GPU内存规模只增长了约三倍.
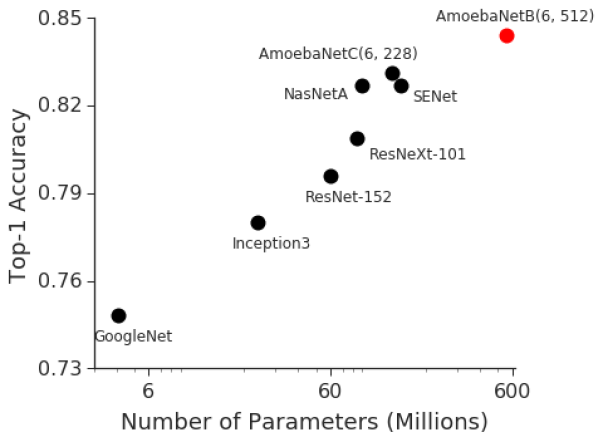
模型规模的扩展意在实现更高的正确率,但会使模型训练愈发具有挑战性。上面的例子说明,依赖改进GPU架构去实现更高效的训练是难以持续的策略,继续实现训练的扩展需要分布式计算方法,将工作负载并行化到各个计算节点上。训练并行化这一理念并不难理解,但是其实现是非常复杂的。开发人员需考虑如何将模型的知识获取分区到不同的节点,随后如何将各部分重新整合为一个整体的模型。训练并行化是深度学习模型扩展的必须手段。针对挑战,谷歌和微软两家公司各自付出了长达多月的努力来做研究和工程化,并分别发布了GPipe和PipDream。
Google GPipe
Gpipe聚焦于扩展深度学习的训练负载。在深度学习模型中,人们常常忽视训练过程的复杂性对架构的影响。训练数据集的规模正越来越大,也越来越复杂。例如在医疗领域,常会涉及需使用数百万张高分辨图像训练的模型。这类模型通常需要很长的训练时间,消耗高昂的内存和CPU成本。
Comments