
导读: Flink从1.9.0开始提供与Hive集成的功能,随着几个版本的迭代,在最新的Flink 1.11中,与Hive集成的功能进一步深化,并且开始尝试将流计算场景与Hive进行整合。本文主要分享在Flink 1.11中对接Hive的新特性,以及如何利用Flink对Hive数仓进行实时化改造,从而实现批流一体的目标。主要内容包括:
Flink与Hive集成的背景介绍
Flink 1.11中的新特性
打造Hive批流一体数仓
01 Flink与Hive集成的背景介绍
为什么要做Flink和Hive集成的功能呢?最早的初衷是我们希望挖掘Flink在批处理方面的能力。众所周知,Flink在流计算方面已经是成功的引擎了,使用的用户也非常多。在Flink的设计理念当中,批计算是流处理中的一个特例。也就意味着,如果Flink在流计算方面做好,其实它的架构也能很好的支持批计算的场景。在批计算的场景中,SQL是一个很重要的切入点。因为做数据分析的同学,他们更习惯使用SQL进行开发,而不是去写DataStream或者DataSet这样的程序。
Hadoop生态圈的SQL引擎,Hive是一个事实上的标准。大部分的用户环境中都会使用到了Hive的一些功能,来搭建数仓。一些比较新的SQL的引擎,例如Spark SQL、Impala,它们其实都提供了与Hive集成的能力。为了方便的能够对接上目前用户已有的使用场景,所以我们认为对Flink而言,对接Hive也是不可缺少的功能。
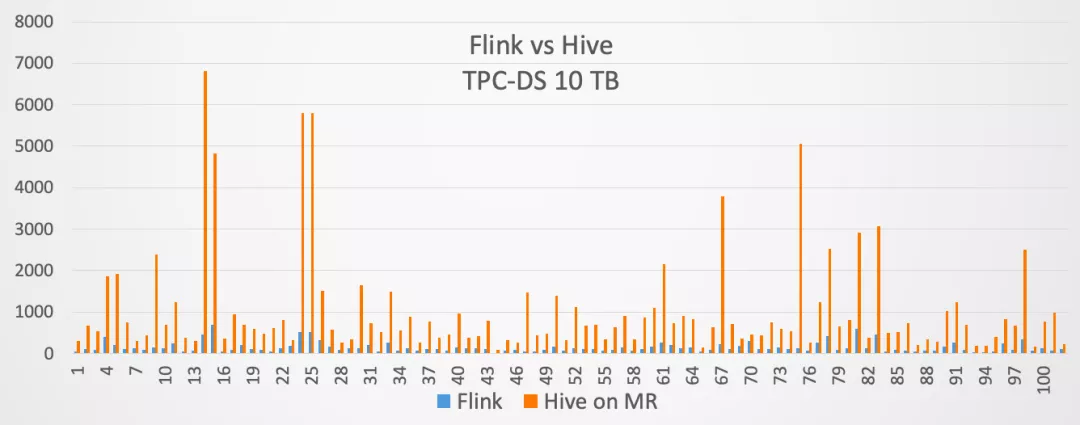
因此,我们在Flink 1.9当中,就开始提供了与Hive集成的功能。当然在1.9版本里面,这个功能是作为试用版发布的。到了Flink 1.10版本,与Hive集成的功能就达到了生产可用。同时在Flink 1.10发布的时候,我们用10TB的TPC-DS测试集,对Flink和Hive on MapReduce进行了对比,对比结果如下:
Comments