
语言模型是指对自然语言文本进行概率建模的模型,它不仅可以估计任意一个给定文本序列的概率,也可以用来预测文本序列中某个位置上词的出现概率,是自然语言处理中最基本的问题。

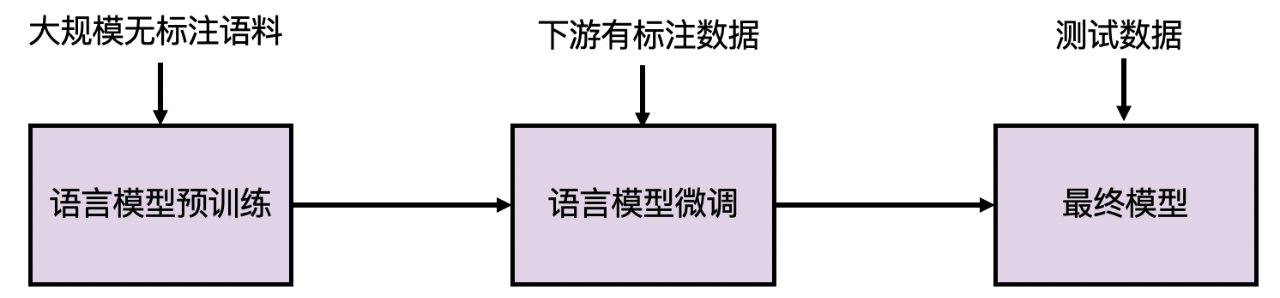
2018年以来,预训练语言模型 (Pretrained Langauge Model, PLM) 的研究风起云涌。与此前有监督学习范式不同的是,预训练语言模型能够充分利用大规模的无标注数据学习通用的语言模型,然后再使用下游任务的少量有标注数据进行模型微调。与直接训练具体任务模型相比,在预训练语言模型基础上微调得到的模型在自然语言处理各大任务上均取得了显著的性能提升。
在 GPU 多机多卡并行算力和海量无标注文本数据的双重支持下,预训练模型实现了参数规模与性能齐飞的局面,取得了人工智能和深度学习领域的革命性突破。国际著名互联网企业和研究机构互相竞争,将模型规模和性能不断推向新的高度。BERT之后,短短两年时间,最新发布的 GPT-3 已经达到1750亿参数规模、上万块 GPU 的惊人训练规模。在人工智能与深度学习领域围绕超大规模预训练模型展开的“军备竞赛”日益白热化,成为对海量数据、并行计算、模型学习能力的全方位考验。
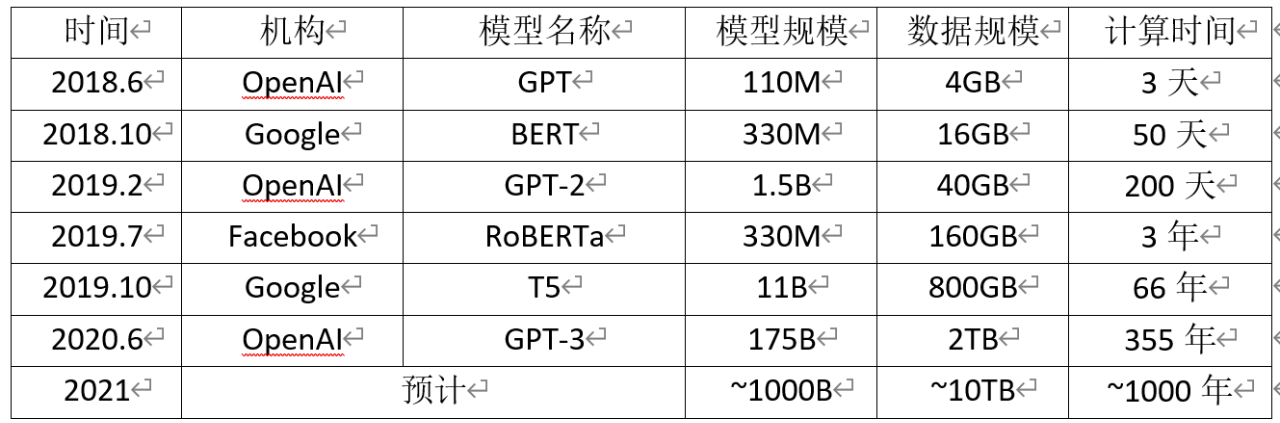
预训练模型规模以平均每年10倍的速度增长 (最后一列计算时间为使用单块NVIDIA V100 GPU训练的估计时间。M-百万,B-十亿)
Comments