
本文由 dbaplus 社群授权转载。
本次分享主要分为三部分。首先介绍流式计算的基本概念, 然后介绍Flink的关键技术,最后讲讲Flink在快手生产实践中的一些应用,包括实时指标计算和快速failover。
一、流式计算的介绍
流式计算的定义: 流式计算主要针对unbounded data(无界数据流)进行实时的计算,将计算结果快速的输出或者修正。
这部分将分为三个小节来介绍。第一,介绍大数据系统发展史,包括初始的批处理到现在比较成熟的流计算;第二,为大家简单对比下批处理和流处理的区别;第三,介绍流式计算里面的关键问题,这是每个优秀的流式计算引擎所必须面临的问题。
1、大数据系统发展史
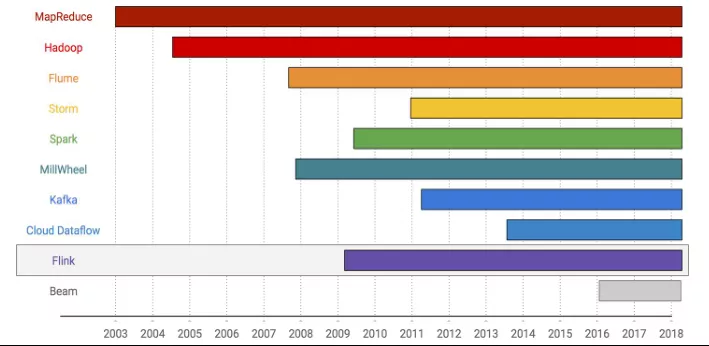
上图是2003年到2018年大数据系统的发展史,看看是怎么一步步走到流式计算的。
2003年,Google的MapReduce横空出世,通过经典的Map&Reduce定义和系统容错等保障来方便处理各种大数据。很快就到了Hadoop,被认为是开源版的MapReduce, 带动了整个apache开源社区的繁荣。再往后是谷歌的Flume,通过算子连接等pipeline的方式解决了多个MapReduce作业连接处理低效的问题。
Comments