
从高资源语言进行迁移学习是一种提高低资源语言端到端自动语音识别(automatic speech recognition,ASR)的有效方法。然而,预训练编码器 / 解码器模型并不能共享同一语言的语言模型,这使得它不适用于外来目标语言。为进一步吸收目标语言的知识,并能从目标语言转换,语音到文本翻译(speech-to-text translation,ST)是辅助任务。
该方法通过语音到文本翻译作为中间步骤,改进了针对端到端自动语音识别的跨语言(高资源到低资源)迁移学习。它使学习迁移成为一个两步过程,提高了模型的性能。
目前,该方法是基于注意力的编码器 / 解码器结构。然而,该团队打算将这种迁移学习方法扩展到端到端架构,如 CTC 和 RNN Transducer。
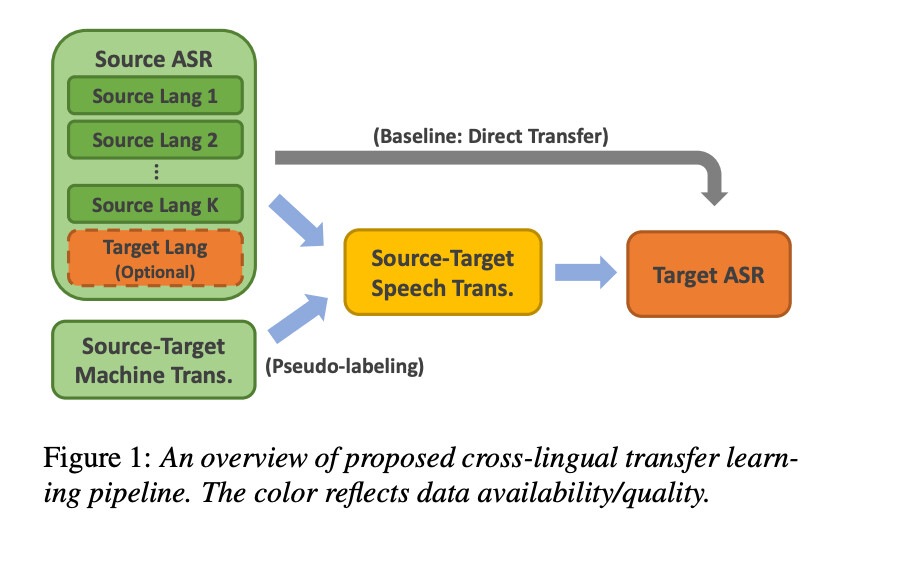
与之前利用转换数据方法不同,这种方法不需要对自动语言识别模型架构进行任何修改。语言到文本翻译和目标自动语言识别都具有相同的基于注意力的编码器 / 解码器架构和词汇表。高资源的自动语音识别转录本被翻译成目标低资源语言来训练语音到文本翻译模型。
Comments