
目标导向的视觉对话是“视觉-语言”交叉领域中一个较新的任务,它要求机器能通过多轮对话完成视觉相关的特定目标。该任务兼具研究意义与应用价值。
日前,北京邮电大学王小捷教授团队与美团AI平台NLP中心团队合作,在目标导向的视觉对话任务上的研究论文《Answer-Driven Visual State Estimator for Goal-Oriented Visual Dialogue-commentCZ》被国际多媒体领域顶级会议ACM MM2020录用。
该论文分享了在目标导向视觉对话中的最新进展,即提出了一种响应驱动的视觉状态估计器(Answer-Driven Visual State Estimator,ADVSE)用于融合视觉对话中的对话历史信息和图片信息,其中的聚焦注意力机制(Answer-Driven Focusing Attention,ADFA)能有效强化响应信息,条件视觉信息融合机制(Conditional Visual Information Fusion,CVIF)用于自适应选择全局和差异信息。该估计器不仅可以用于生成问题,还可以用于回答问题。在视觉对话的国际公开数据集GuessWhat?!上的实验结果表明,该模型在问题生成和回答上都取得了当前的领先水平。
背景
一个好的视觉对话模型不仅需要理解来自视觉场景、自然语言对话两种模态的信息,还应遵循某种合理的策略,以尽快地实现目标。同时,目标导向的视觉对话任务具有较丰富的应用场景。例如智能助理、交互式拾取机器人,通过自然语言筛查大批量视觉媒体信息等。
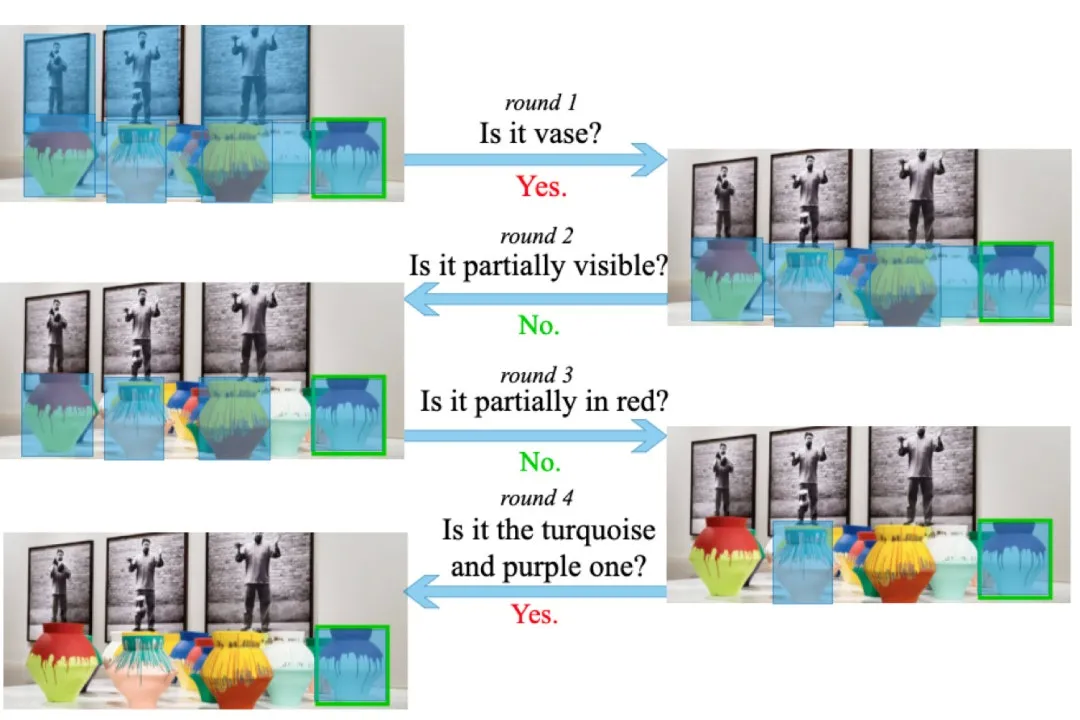
研究现状及分析
为了进行目标导向的和视觉内容一致的对话,AI智能体应该能够学习到视觉信息敏感的多模态对话表示以及对话策略。对话策略学习的相关工作有很多,如Strub等人[1]首先提出使用强化学习来探索对话策略,随后的工作则着重于奖励设计[2,3]或动作选择[4,5]。但是,它们中的大多数采用了一种简单的方式来表示多模态对话,分别编码两个模态信息,即由RNN编码的语言特征和由预训练CNN编码的视觉特征,并将它们拼接起来。
好的多模态对话表示是策略学习的基石。为了改进多模态对话的表示,研究者们提出了各种注意机制[6,7,8],从而增强了多模态交互。尽管已有工作取得了许多进展,但是还存在一些重要问题。
Comments