
语音分离(Speech Separation),就是在一个有多个说话人同时说话的场景里,把不同说话人的声音分离出来。目标说话人提取(Target Speaker Extraction)则是根据给定的目标说话人信息,把混合语音当中属于目标说话人的声音抽取出来。
下图汇总了目前主流的语音分离和说话人提取技术在两个不同的数据集上的性能,一个是 WSJ0-2mix 纯净数据集,只有两个说话人同时说话,没有噪声和混响。WHAM是与之相对应的含噪数据集。可以看到,对于纯净数据集,近两年单通道分离技术在 SI-SDRi 指标上有明显的进步,图中已PSM方法为界,PSM之前的方法都是基于频域的语音分离技术,而PSM之后的绝大多数(除了deep CASA)都是基于时域的语音分离方法。
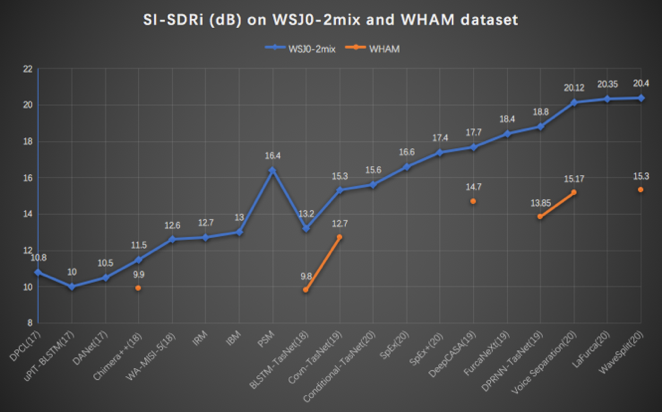
噪声场景相对更贴近于真实的环境。目前,对于噪声场景下的分离技术性能的研究还不是特别完备,我们看到有一些在安静环境下表现比较好的方法,在噪声环境下性能下降比较明显,大多存在几个 dB 的落差。同时,与纯净数据集相比,噪声集合下各种方法的性能统计也不是很完备。
通常来讲,单通道语音分离可以用“Encoder-Separator-Decoder”框架来描述。其中, Encoder可以理解为将观测信号变换到另外的一个二维空间中,比如离散傅里叶变换将时域信号变换到频域,1-D CNN将时域信号变换到一个二维潜空间中;Separator在变换域当中进行语音的分离,学习出针对不同声源的mask,与混合信号做一个元素级别相乘,由此实现变换域中的语音分离操作;Decoder 就是把分离后的信号反变换到一维时域信号。这套框架既可适用于频域的分离方法,也可用于时域的分离方法。
Comments