
BERT,全称 Bidirectional Encoder Representation from Transformers,是一款于 2018 年发布,在包括问答和语言理解等多个任务中达到顶尖性能的语言模型。它不仅击败了之前最先进的计算模型,而且在答题方面也有超过人类的表现。招商证券希望借助BERT提升自研NLP平台的能力,为旗下智能产品家族赋能。
在前一篇蒸馏模型中,招商证券信息技术中心 NLP 开发组已经初步实践了BERT模型压缩方法,成功将12层BERT模型缩减为3层。在本次分享中,研发人员们将介绍更简洁的模块替换方法,以及削减参数比特位的量化方法,并将这几种方法有机结合实现了将BERT体积压缩至1/10的目标。
1. BERT-of-Theseus模块替换
1.1 概述
BERT-of-Theseus[1]主要通过模块替换的方法进行模型压缩。不同于模型蒸馏方法需要根据模型和任务制定复杂的损失函数以及引入大量额外超参,Theseus压缩方法显得简洁许多:该方法同样需要一个大模型作为“先驱”,而规模较小的目标模型作为“后辈”(类似蒸馏方法中的教师模型和学生模型),对于“先驱”BERT模型来说,主体部分是由多个结构相同的Transformer Encoder组成,“后辈”模型将“先驱”中的每N个Transformer Encoder模块替换为1个Transformer Encoder模块,从而实现模型的压缩。具体实现过程如下:
在BERT模型中,第i个Encoder的输出为:
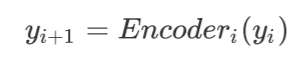
“先驱”和“后辈”中第i个模块的输出分别为:
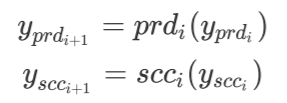
Comments